Info
Tags: Challenge, Sensitive Data Exposure, JavaScript, Web Security
Description
Mission brief
Cross-domain iframe communication? Sounds insecure…
Instructions
Hello there!
Your task is simple:
- Craft an attacker page which steals the secret token of visitors
Two web applications belong to this challenge:
- Webservice
- Attacker page
You have to create a PoC exploit using the WebIDE and if it’s ready, simply press “Check solution” above. Our user will visit your attacker page
and if his token pops up in an alert box, then your solution will be
accepted.
Have fun and please do not use external resources in your payload, otherwise your solution will be rejected.
Enumeration
I got access to 2 pages.
An attacker one(which needed to steal the token from the main page):
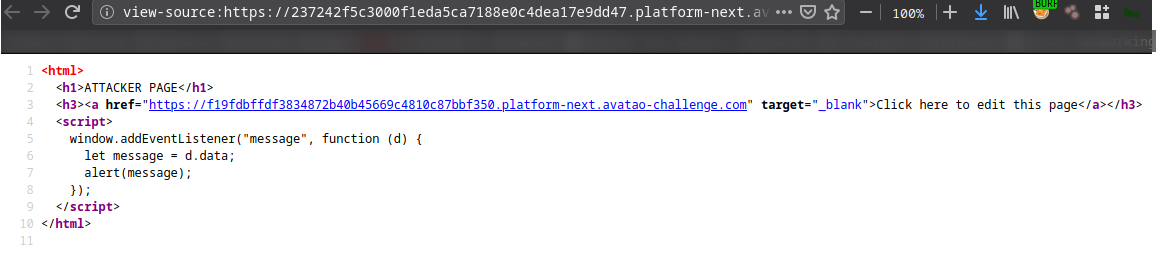
Main page and attacker page editor:
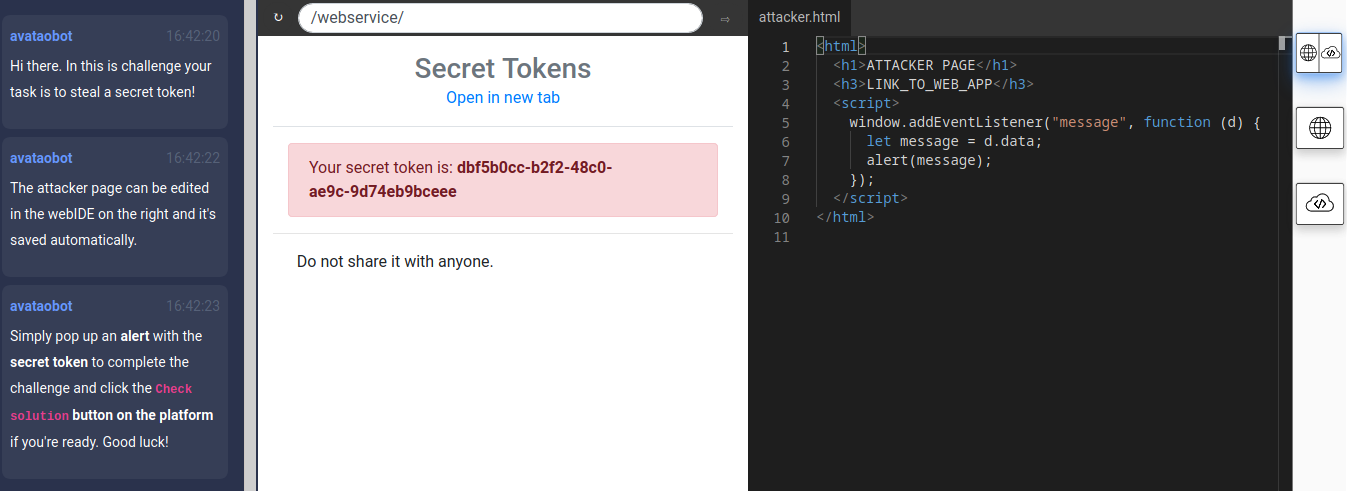
I clicked on Open in new tab in order to be able to look into the source of the target page.
Source code of the target page:
|
|
- There was an iframe included on the page
|
|
I clicked on it to take a look at the source.
|
|
-
There were a whitelist
1 2 3 4avatao.com https://f19fdbffdf3834872b40b45669c4810c87bbf350.platform-next.avatao-challenge.com/webservice localhost avatao-challenge.com -
It checked if my URL ended with one of the whitelisted domains
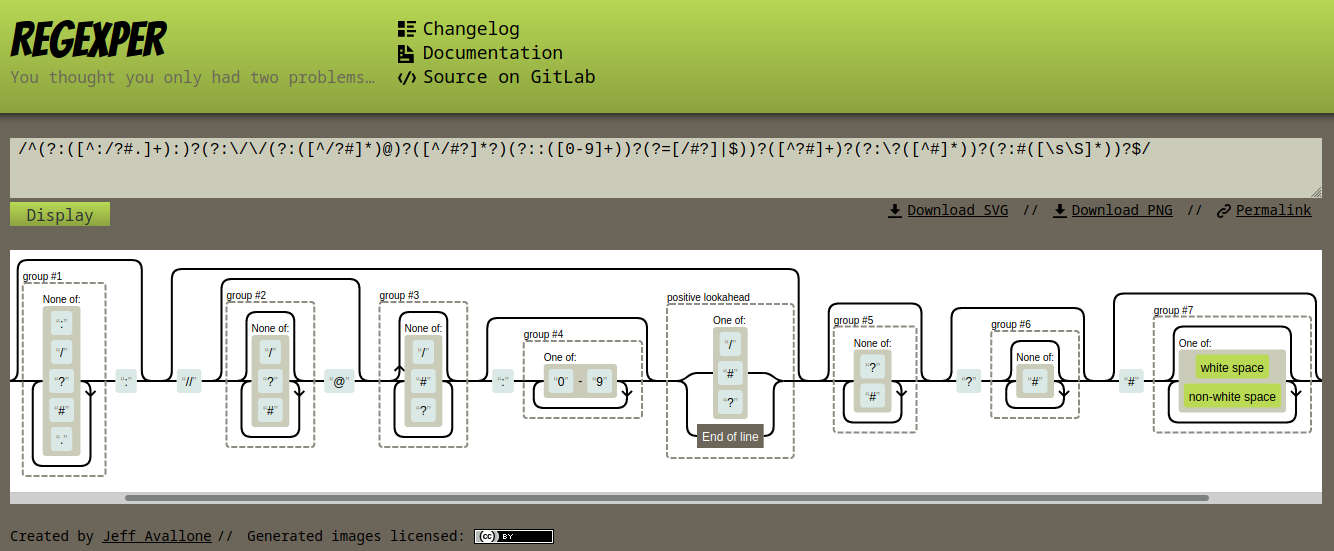
There were also a long regex(for checking the validity of the URI).
I copied it and pasted into https://regexper.com in order to see it visually.
https://tools.ietf.org/html/rfc3986#section-3.2
https://tools.ietf.org/html/rfc2396
https://i.blackhat.com/asia-19/Fri-March-29/bh-asia-Wang-Make-Redirection-Evil-Again-wp.pdf
I also used devtools to check the regex with a full-featured URL.
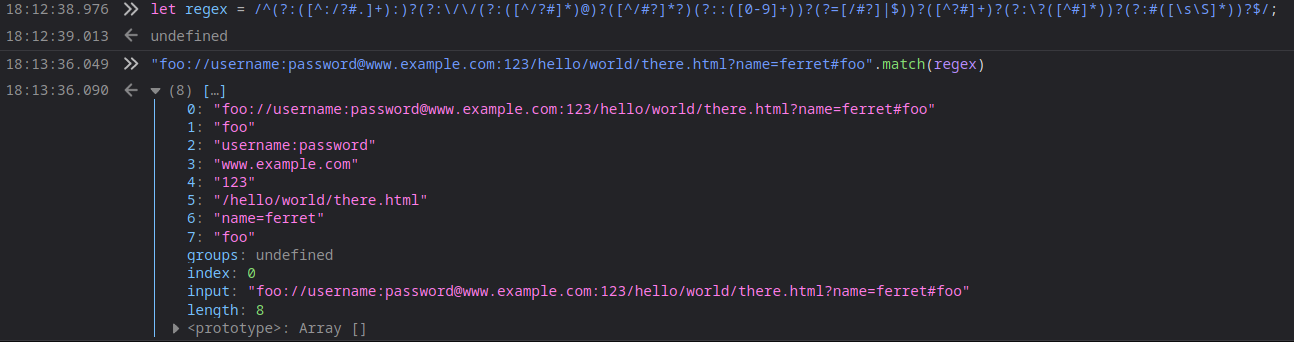
|
|
- In this case
let origin = url.match(regex)[3];meantwww.example.comwhich was the HOST regarding to the RFCs(https://tools.ietf.org/html/rfc3986#section-3.2, https://tools.ietf.org/html/rfc2396) and the other pdf(https://www.notion.so/Secret-Token-7daf27c69c31444d944e54bc03c7a094#9434a427202540f29c12e2961899b010)- This domain needs to be in the whitelist.
- Also note that the whitelist check happens before the regex check
- Regarding to the visualized regex
group3had 3 characters on a blacklist:/,#, and?
Exploitation
There should be a way to bypass these restrictions but the RFC didn’t help.
https://hackerone.com/reports/431002
https://i.blackhat.com/asia-19/Fri-March-29/bh-asia-Wang-Make-Redirection-Evil-Again-wp.pdf
https://medialize.github.io/URI.js/about-uris.html
Authority: this is the most complicated and problematic part. Several points to notice:(a) All special characters in user-info, except the last@, is URL-encoded. (b) In special schemes, e.g., HTTP and FTP,
\is treated as path separator, which serves the same purpose as/. (c) Any one of\,/,#and?first appeared in the URL istreated as the separator between authority regardless of which component it is in.
- There is the separator I need!
\
I checked \ against the regex using dev-tools again and everything was fine!
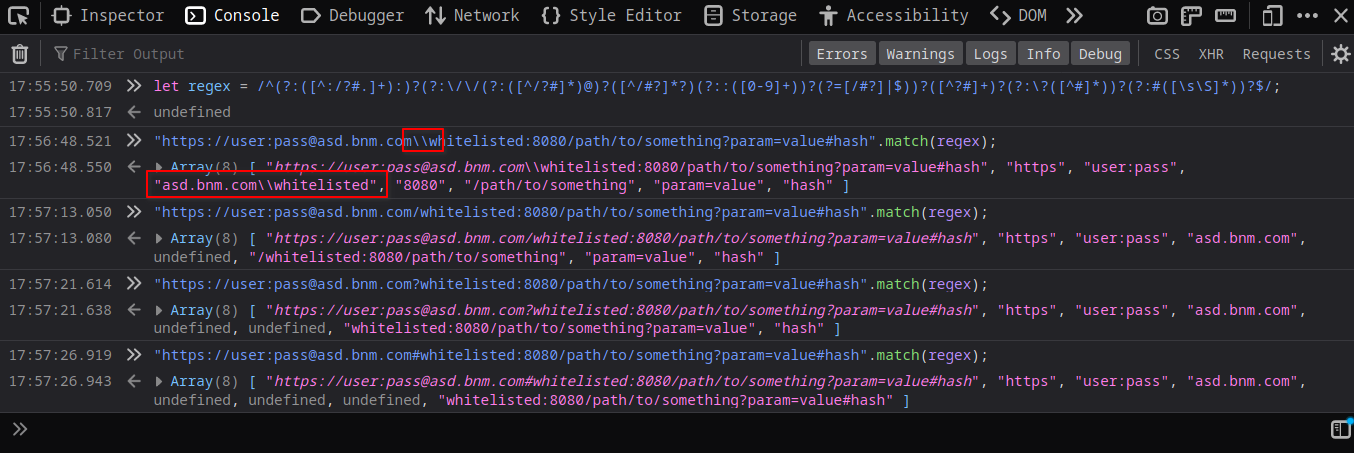
It was time to try out \ on the target!
My payload should look like this:
https://<victim>/webservice/iframe?parent_origin=<evil>\\<whitelist>
My payload with the iframe tag:
|
|
My full payload:
https://f19fdbffdf3834872b40b45669c4810c87bbf350.platform-next.avatao-challenge.com/webservice/iframe?parent_origin=https://237242f5c3000f1eda5ca7188e0c4dea17e9dd47.platform-next.avatao-challenge.com\\localhost
Which looked like this in the PoC:
|
|
Full PoC source:
|
|
I hit F5 on the attacker page and I successfully got the token!
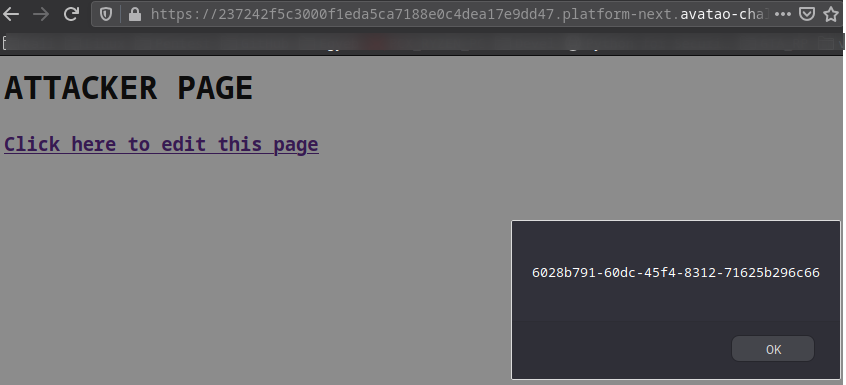
- I got the token! → Challenge completed!
Takeaways:
- RFCs are good but research pages and other standards can help too!
- If there is a regex for URI validation just put it into a “regex explainer”
- If there is a whitelist try to bypass it with the use of delimeters(
\,/,?,#,@)
EXRTA CREDIT: David Schütz
This url parsing regex vulnerability was a real bug in google’s main library.
David wrote a great article about his findings so make sure you check it out: